
|
|
Aktuell information för kursen SF1922/SF1923 Sannolikhetsteori och statistik, 6hp, för CTFYS1/CMEDT2, period 4, vt 2018.
Här ges fortlöpande information om schemaändringar, vad som gåtts igenom på föreläsningar etc.
Laboration 2Se till att komma till labbsalen minst tio minuter före redovisningstiden så att ni hinner logga in på datorn och öppna Matlab samt ta fram era redovisningsuppgifter. Skriv även upp vilken dator ni sitter vid på whiteboarden i datorsalen, så att labbassistenten lätt hittar er när redovisningstiden börjar. Ni behöver också ha med er en utskrift av labbspecifikationen som ni har skrivit era personnummer på förstasidan på. Denna utskrift undertecknar labbassistenten efter att hen har godkänt labben och utskriften fungerar sedan som ert kvitto på resultatet. Föreläsningar2018-05-14 Fjortonde föreläsningen. Slides finns här.
2018-05-08 Trettonde te föreläsningen. Slides finns här.
Fortsätt diskutera exempel om rattfylleri och presenterade tre metoder för att utföra hypotestest: direktmetoden eller p-varde, testvariabel och kritisk område samt konfidensmetoden. I samband med detta exempel pekades på den i praktiska sammanhang ofta användbara konfidensmetoden att utföra hypotesprövning på nivån α genom att beräkna ett konfidensintervall med konfidensgrad (1-α). Begreppet styrkefunktion introducerades och används för att se hur bra ett test skiljer H_0 från H_1 i exempel med rattfylleri.
2018-05-04 Tolfte föreläsningen. Slides finns här.
Pekade på att det är viktigt att kunna identifiera om data kommer från "två oberoende stickprov" eller "stickprov i par" då man löser tentauppgifter! Sedan presenterades intervallskattning med normalapproximation. Inledning om Kapitel 13 om hypotesprövning, dvs statistisk bevisning. Grundbegreppen nollhypotes, alternativhyptotes, testvariabel, kritiskt område, signifikansnivå (felrisk) illustrerades med exemplet om skicklig slantslingning. Testvariabel- och direktmetoden visades. Läs mer om test av astrologer som används som exempel. 2018-04-24 Elfte föreläsningen. Slides finns här.
Repeterade konfidensintervall för μ vid normalfördelade observationer med känd respektive okänd spridning. Då dök t ex t(n-1)-fördelningen upp. Bild på t(9)-fördelningen
Konstruktion av konfidensintervall för σ som kan studeras i FS 12.4. Dårvid dök χ2-fördelningen upp. Bild på χ2(9)-fördelningen.
Diskuterade och illustrerade konfidensintervall för situationen "två oberoende stickprov" samt "parvisa observationer" och framhöll vikten av att kunna skilja detta från "två oberoende stickprov". Gå själv genom exempel för "stickprov i par" i slides. Hann inte prata om approximativa konfidensintervall. Ska ta upp den under nästa föreläsning.
2018-04-20 Tionde föreläsningen. Slides finns här.
Föreläsning 10 inleddes med fördjupade diskussionen om punktskattningarnas egenkaper. Sedan introducerades begreppet konfidensintervall, illustrerat på skattning av väntevärde i normalfördelnig med känd standardavvikelse (se exempel 12.1 och 12.2 i boken). Sedan berättade jag om fallet med okänd standardavvikelse, som då måste skattas (med stickprovsstandardavvikelsen). Den generella arbetsgången för att ta fram ett konfidensintervall är som följer: (i) definiera (och inför beteckning för) den parameter som skall skattas, (ii) hitta en (punkt)skattare av denna parameter, (iii) beräkna fördelningen för skattaren (denna fördelning innehåller parameterar, speciellt den som skall skattas), (iv) hitta en transformation av skattaren (i regel en subtraktion av och/eller division med parameterar, stickprovsstorlek o dyl) till en ny stokastisk variabel (en s k pivotvariabel) vars fördelning 2018-04-17 Nionde föreläsningen. Slides finns här.
Inledning om det viktiga kapitel 11 om punktskattningar med utgångspunkt i exemplet om opinionsundersökning beskrivet i avsnitt 11.2 i läroboken. Allmänt om punktskattningar med begreppen parameter, statistisk modell, punktskattning och stickprovsvariabel (skattare). Begreppen väntevärdesriktigtighet, konsistens, effektivitet och medelkvadratfel. Pratade om hur man skattar μ respektive σ2 då data är utfall av oberoende likafördelade stokastiska variabler med väntevärde μ och varians σ2. Aritmetiskt medelvärde och s2 utgör väntevärdesriktiga och konsistenta skattningar. Det kan dock finnas effektivare skattningar i speciella situationer och här är ett Maximum likelihoodmetoden diskuterades kort på slutet med ett exempel med Binomial fördelade mätdata. ML-metoden ger i princip de effektivaste skattningarna. För den (mycket) intresserade ges här en (ganska svår) genomgång av teoretisk statistik. ML och MK skattnings metoder ska tas upp under nästa föreläsningen. Läs själva i boken!
2018-04-16 Åttonde föreläsningen. Slides finns här.
Diskuterade egenskapen att alla linjärkombinationer av oberoende normalfördelade stokastiska variabler är normalfördelade.
Vidare presenterades det viktigaste resultatet i matematisk statistik, nämligen centrala gränsvärdessatsen. Denna kan exemplifieras med poängsumma av många tärningskast: 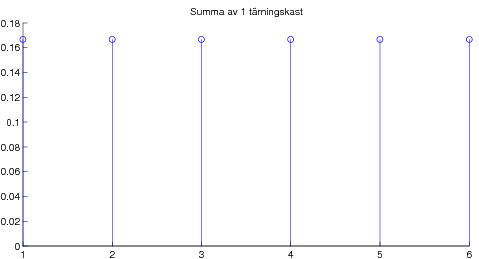 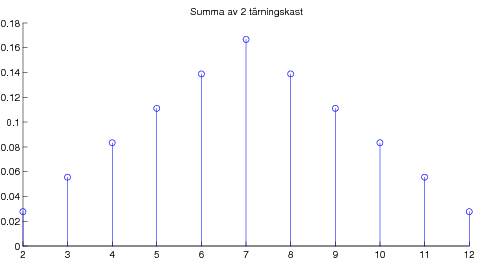 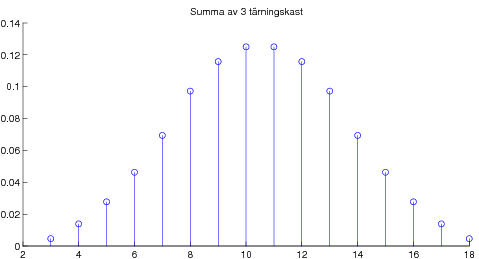 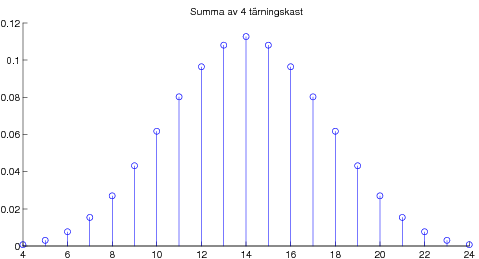 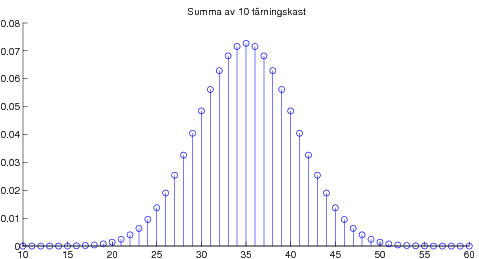 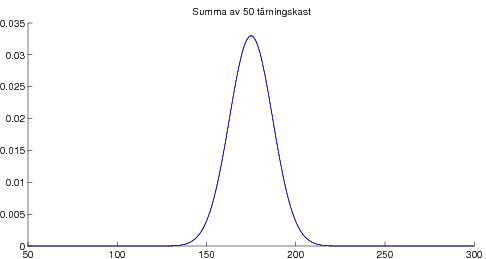
Kapitel 7 om binomialfördelning och dess släktingar. Om binomialfördelning. Typsituationerna för binomialfördelningen. Framställning av binomialfördelningen som fördelning för summa av indikatorer. Detta användes för att ta fram väntevärde och varians för binomialfördelningen. Som exempel kan mant ta: Antalet 6:or i 20 tärningskast, dvs Bin(20,1/6)-fördelningen samt Antalet väljare från ett parti med 4% i väljarkåren i ett urval 1000 slumpmässigt utvalda, dvs Bin(1000,0.04)-fördelningen. Normalapproximation av binomialfördelningen med Centrala gränsvärdessatsen. Läs själva i boken sats om att summan av oberoende Poisson-fördelade stokastiska variabler är Poisson-fördelad. Detta kan bevisas med hjälp av sannolikhetsgenererande funktion (ligger lite utanför kursen). Kan också bevisas direkt med hjälp av faltning. Normalapproximation av Poisson-fördelning med Centrala gränsvärdessatsen. 2018-04-13 Sjunde föreläsningen. Slides finns här.
Föreläsning 7 behandlade normalfördelningen. Vi undersökte först den standardiserade normalfördelningen och dess täthets- och fördelningsfunktioner samt visade hur fördelningsfunktioner och kvantiler kan bestämmas ur tabeller. Vi diskuterade sedan allmänna normalfördelningar och visade hur dessa kan överföras till standardiserade normalfördelningar med hjälp av en linjär transformation (subtrahera väntevärdet och dividera med standardavvikelsen). Vi noterade att linjärkombinationer av oberoende normalfördelade stokastiska variabler är normalfördelade och att det aritmetiska medelvärdet av oberoende normalfördelade stokastiska variabler är normalfördelat. Som varning för att det krävs någon form av oberoende för att summor av normalfördelade stokastiska variabler skall bli normalfördelade ges följande motexempel. Vi avslutade med att diskutera centrala gränsvärdessatsen, som säger att även aritmetiska medelvärden av n st. oberoende, likafördelade (men inte nödvändigtvis normalfördelade) stokastiska variabler är approximativt normalfördelade för stora värden på n. För den intresserade: Ett bevis av centrala gränsvärdessatsen med hjälp av Laplacetransform (momentgenererande funktion) samt ett bevis med hjälp av Fourier-transform (karakteristisk funktion). 2018-04-10 Sjätte föreläsningen. Slides finns här. Under föreläsning 6 fortsätter vi diskutera två-dimensionella s.v., diskreta och kontinuerliga. Viktigt är att "se igenom" alla formler, och se att det fortfarande är samma grundideer som i en dimension: sannolikheter för att en två-dimensionell s.v. ligger i ett område fås genom att summera två-dim sannolikhetsfunktion, eller integrera två-dim täthetsfunktion, över området; väntevärdet av en funktion av en två-dim s.v. fås genom att beräkna funktionsuttrycket för alla (två-dim) utfall av de s.v., sedan vikta med sannolikhetsfunktion eller täthet, och slutligen summera eller integrera över alla utfall. Vi noterade också att väntevärdet är linjärt, dvs att väntevärdet av en linjärkombination av s.v. alltid är lika med motsvarande linjärkombination av väntevärdena av de olika s.v. Vi definierade också begreppet kovarians, som är ett mått på linjärt beroende mellan två s.v. Vi visade också att kovariansen är bilinjär (dvs har linjäritetsegenskapen i båda argumenten; tänk på multiplikation av summor av termer inom paranteser), och att variansen av en s.v. är kovariansen av denna med sig själv (V(X)=C(X,X)). Vet man och kan använda detta så klarar man alla beräkningar med väntevärden och (ko)varianser! Vi härledde att oberoende s.v. också är okorrelerade, dvs har kovarians 0. Föreläsningen avslutades med en presentation av stora talens lag, dvs att aritmetiska medelvärdet av summor av oberoende likafördelade stokastiska variabler konvergerar mot väntevärdet, vilket är en viktig tolkning av väntevärdet. Som specialfall kan man ta "relativa frekvensers stabilitet" som vi talade om i kapitel 2. 2018-03-29 Femte föreläsningen. Slides finns här. Föreläsning 5 handlade om två-dimensionella s.v., diskreta och kontinuerliga. Viktigt är att "se igenom" alla formler, och se att det fortfarande är samma grundidéer som i en dimension: sannolikheter för att en två-dimensionell s.v. ligger i ett område fås genom att summera två-dim sannolikhetsfunktion, eller integrera två-dim täthetsfunktion, över området; väntevärdet av en funktion av en två-dim s.v. fås genom att beräkna funktionsuttrycket för alla (två-dim) utfall av de s.v., sedan vikta med sannolikhetsfunktion eller täthet, och slutligen summera eller integrera över alla utfall. Vi gick igenom marginalisering för att få sannolikhets- eller täthetsfunktionen för bara den ena komponenten av en två-dim s.v. Vi definierade begreppet oberoende s.v., och att den två-dim sannolikhets- eller täthetsfunktionen i så fall är produkten av de marginella (endimensionella) dito. Vi gick också igenom hur man får fram fördelningen för minimum, maximum av oberoende s.v. 2018-03-27 Fjäre föreläsningen. Slides finns här. Föreläsningen handlade om kontinuerliga stokastiska variabler. Jag började med repetition av de viktiga begreppen diskret fördelning och övergick till definition av kontinuerlig stokastisk variabel. En sådan stokastisk variabel kan anta alla värden på tallinjen, eller ett intervall av reella tal. Man kan säga att den totala sannolikhetsmassan 1 är kontinuerligt utsmetat på tallinjen (eller ett intervall). Precis hur sannolikhetsmassan är fördelad beskrivs av täthetsfunktionen, som är det viktigaste begreppet för kontinuerliga stokastiska variabler, och motsvarar sannolikhetsfunktionen för diskreta dito. En grundprincip är att sannolikheten att en kontinuerlig stokastisk variabel faller i en viss delmängd av tal (t ex ett intervall), fås genom att integrera täthetsfunktionen över denna mängd.
Begreppet fördelningsfunktion dvs FX(x)=P(X≤x) diskuterades kort. Jag återkommer till den under nästa föreläsning. Fördelningsfunktion
kan användas för att beräkna
FX(b)-FX(a)=P(a < X≤b)=P(a≤ X ≤b)=P(a < X < b)= P(a ≤ X < b) eftersom P(X=x0)=0 oavsett x0. Viktigt är också hur väntevärdet av (en funktion av) en kontinuerlig stokastisk variabel definieras/beräknas. Notera att definitionen är analog med motsvarande för en diskret stokastisk variabler, men vi byter sannolikhetsfunktion mot täthet och summa mot integral. Begreppet kvantil hann jag inte diskutera. Läs själva i boken! Vi återkommer också till kvantiler under statistikavsnittet av kursen. 2018-03-23 Tredje föreläsningen. Slides finns här.
Föreläsning 3 handlade om diskreta stokastiska variabler. Begreppen stokastisk variabel, diskret stokastisk variabel och sannolikhetsfunktion definierades, liksom begreppet väntevärde (för diskreta s.v.). Jag gick igenom ett antal viktiga diskreta fördelningar:
2018-03-22 Andra föreläsningen. Slides finns här. Repeterade grundläggande terminologi (slumpmässigt försök, utfall, utfallsrum och händelse), Kolmogorovs axiomsystem och begreppen "Med/Utan återläggning" samt "Med/utan ordningshänsyn". Exempel presenterades dår sannolikheten härleds för att få k vita kulor då man ur en urna med v vita och s svarta kulor drar n kulor med respektive utan återlåggning. Vidare introducerades betingad sannolikhet som var huvudtema av föreläsning 2. Viktiga räkneprinciper är total sannolikhet och, för att "vända på betingning", Bayes sats. En illustration av Bayes sats ges på slutet med exempel av sjukdomsdiagnostik. Läs själva mer om ett diagnostiskt test, Bayes sats och positiva resultat i mammografi i en artikel från Scientific American January 2012. Betingad sannolikhet används för att introducera begreppet oberoende händelser. Skilj noga mellan oberoende och disjunkta! Jag återkommer till detta i början av nästa föreläsning. För n stycken oberoende händelser, A1, A2, ... An, sannolikheter att alla, ingen och någon inträffar diskuterades. Läs gärna igenom avsnitt 2.7 i boken extra ordentligt!
Under nästa föreläsning ska begreppet stokastiska variabler (Kap. 3) introduceras och det diskreta fallet diskuteras utförligt.
2018-03-20 Första föreläsningen. Slides finns här.
Föreläsning 1 innehöll introduktion till kursen samt kort presentation av deskriptiv statistik. Vidare grundläggande terminologi, slumpförsök, utfall, utfallsrum och händelse med exempel på diskreta utfallsrum diskuterades. Tolkning av mängder som händelser och mängdlärans operationer: komplement, union och snitt. De Morgans lagar. Omöjliga och oförenliga (disjunkta) händelser. Tolkning av sannolikhetsbegreppet. Relativa frekvensers stabilitet. Kolmogorovs axiomsystem och några satser som följer ur detta. Klassisk sannolikhetsdefinition som är tillämplig då elementarutfallen kan anses vara lika sannolika. Kort om kombinatorik, dvs svaret på frågan "På hur många sätt kan man....", multiplikationsprincipen med exempel (hann inte, finns på slides, jag ska åtrkomma till detta under Fls 2). Läs själva avsnitt 2.5, a) och b) i boken där två urnmodeller använd för att illusterera dragning utan och med återläggning. Detta vidare har kopplingar till Binomialfördelningen och Hypergeometriska fördelningen som presenteras i kapitel 3 och 7.
|
 |
|
Sidansvarig: Tatjana Pavlenko Uppdaterad: 2018-03-21 |