
|
|
Aktuell information för kursen SF1910 Tillämpad statistik,
7.5hp, för CSAMH, period 2, ht 2016.
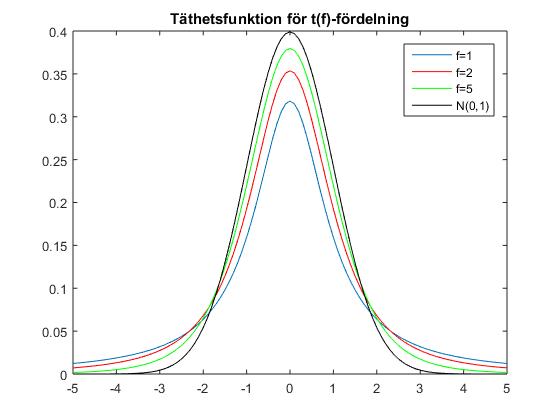
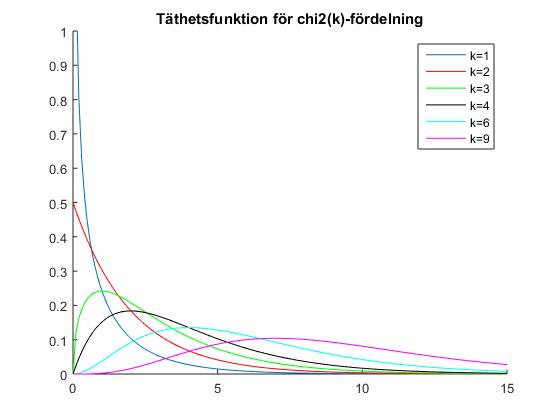
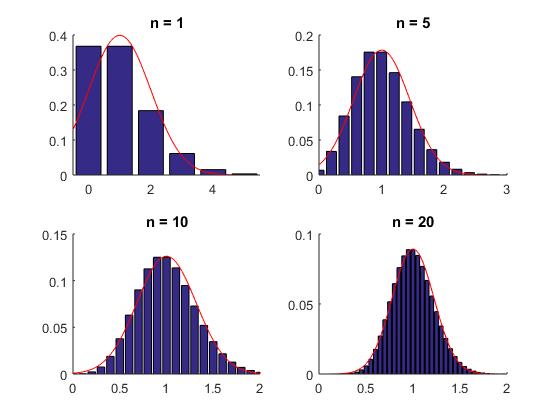
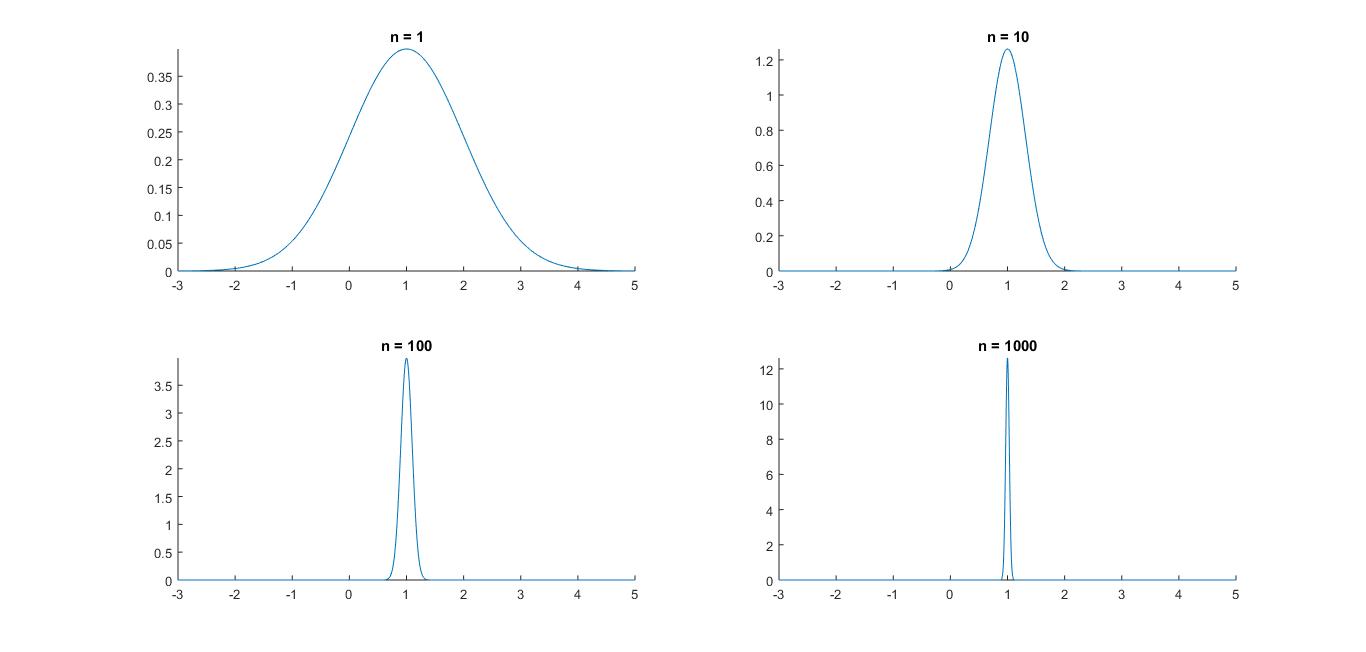
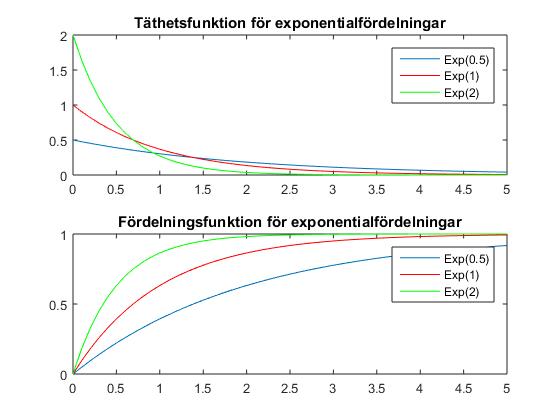
Här ges fortlöpande information om schemaändringar, vad som gåtts igenom på föreläsningar etc. Anmälan till omtentamen 13 april 2017Anmälningssystemet för omtentor i P2 är öppet 27 febr - 27 mars 2017 (det är alltså redan öppet). Omtentamen i SF1910 går torsdag 13 april kl 8.00-13.00.Norm för tentamen 20170901Nu finns den norm som använts vid rättningen av tentemen 20170109 i arkivet för gamla tentor, alternativt kan du klicka här.Tentamen 20170901 rättadResultaten från tentamen 9 januari 2017 är nu klara och finns i Rapp. De borde finnas i Ladok under fredag 27/1. Tentamen är lämnad till scanning och borde scannas under vecka 5. Även projekten ligger inne i Rapp och borde dyka upp i Ladok under vecka 5.Tentamen 20170901Tentamen med lösningar hittar du härProjektarbetetHär är hemsidan för projektarbetet! Om ni har frågor eller funderingar angående projektarbetet så kan ni höra av till Han-Suck Song med e-mail: han-suck.song@abe.kth.se så ser han till att frågan hamnar rätt.Tidsbokning för redovisning av laboration 2OBS!!! Ni måste boka in er senast 23/12 kl 23.59! Tag med er en utskrift av lab-instruktionen på vilken ni skrivit namn och personnummer, så får ni en signatur på det som kvitto på att ni är godkända. Spara sedan den påskrivna instruktionen tills poängen för laborationen rapporterats in. Se till att komma i tid till redovisningen, så att ni hinner logga in och ta fram era redovisningsuppgifter, annars kommer redovisningsschemat inte hålla och ni riskerar att bli underkända. RappTryck på "Deltar i kursen" i Rapp. Det verkar inte finnas något alternativ som är "activate".KontrollskrivningSista dag för anmälan till kontrollskrivningen 22/11 är tisdagen den 8 november 2016.FöreläsningsinformationFöreläsning 15 (161214)På föreläsning 15 gick vi igenom tal 1, 3, 6 och 8 från gamla tentamensuppgifter.Föreläsning 14 (161212)Föreläsningen började med en introduktion till regressionsanalys. Linjär regression används för att undersöka om det finns en linjärt samband, en regressionslinje, mellan två storheter.Resten av föreläsningen ägnades åt chi2-test. Vi visade hur man kan testa hypotesen att data kommer från en given fördelning med skattade parametrar. Därefter fortsatte vi med homogenitetstest (test av om flera serier har samma fördelning) och nämnde även oberoendetest (test av om två egenskaper är oberoende). För den (mycket) intresserade ges här en (ganska svår) genomgång av teoretisk statistik. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 13 (151211)Föreläsning 13 började med att tal 13.8 löstes. Sedan infördes bereppet styrkefunktion och övning 12.4 i de alternativ övningshäftet (som är en fortsättning på 13.8) löstes. En illustration av användningen av styrkefunktionen finns i följande exempel om rattfylleri.Resten av föreläsningen ägnades åt chi2-test. Vi visade hur man kan testa hypotesen att data kommer från en given fördelning med kända parametrar. Jag såg att jag enligt föreläsningsplanen skulle pratat om linjär regression. Jag har också förstått att vissa har detta i sina projekt. Jag ber om ursäkt för detta. Linjär regression kommer att gås igenom på måndag 12/12. För den som behöver det går det dock bra att läsa sidorna 358-366 i boken. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 12 (151208)Föreläsning 12 ägnades åt hypotesprövning, vilket innebär att med matematiska metoder avgöra om en uppställd hypotes stöds av de givna observationerna eller ej. Vi introducerade grundbegreppen nollhypotes, mothypotes, testvariabel, kritiskt område, signifikansnivå (felrisk) och p-värde samt illustrerade begreppen med två exempel, förutspå slantsingling och fortkörning. Ett annat exempel kan ni läsa om här.Vi avslutade med att titta på hur konfidensintervall kan utnyttjas för att pröva hypoteser och tog ett exempel där hypotesen gällde väntevärdet för ett normalfördelat stickprov. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 11 (161130)På föreläsning 11 fortsatte vi att studera konfidensintervall.Först studerade vi två oberoende stickprov från två olika normalfördelningar och bestämde ett konfidensintervall för skillnaden mellan de båda normalfördelningarnas väntevärden. Det blev tre olika fall beroende på om man antog att standard avvikelserna var a) kända, b) okände med samma för bägge stickproven, eller c) olika och okända. I fallet c) används approximativa metoden som man hamnar i då stickprovsvariablen är approximativt normalfördelad. Som exempel på approximativa metoden tittade vi på en opinionsundersökning. Avslutningsvis tittade vi på hur man behandlar stickprov i par. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 10 (161128)Föreläsning 10 behandlade konfidensintervall, som kan användas för att ge ett mått på osäkerheten i en punktskattning. Vi tog fram en procedur för att bestämma konfidensintervall och tillämpade denna på två olika typer av konfidensintervall för normalfördelade stickprov.Först undersökte vi konfidensintervall för väntevärdet av ett normalfördelat stickprov i fallet då standardavvikelsen är känd. I detta fall kan vi använda kvantiler för den standardiserade normalfördelningen, se tabellsamlingen. Vi bestämde därefter konfidensintervall för väntevärdet när standardavvikelsen är okänd och i detta fall kan vi använda kvantiler för t-fördelningen, se tabellsamlingen. Se även Figur 8 för exempel på täthetsfunktioner för t-fördelningar. För konfidensintervall för standardavvikelsen av ett normalfördelat stickprov med okänt väntevärde kan man använda kvantiler av chitvå-fördelningen, se tabellsamlingen. Se även Figur 9 för exempel på täthetsfunktioner för chitvå-fördelningar. Detta togs inte upp på föreläsningen, utan detta måste ni läsa om själva!!!!!! Se boken s 296-297. En allmän metodik för att bestämma konfidensintervall finns här och den innehåller också de tre fallen ovan. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 9 (161125)Föreläsning 9 var första föreläsningen om statistikteori. Givet ett slumpmässigt stickprov med numeriska mätdata vill vi uppskatta en eller flera parametrar (exempelvis väntevärdet eller variansen) i den fördelning som stickprovet antas komma från. Vi introducerade begreppet punktskattning, som är en funktion av stickprovet som för varje stickprov ger ett värde på den okända parametern. Stickprovet x kan ses som ett utfall av en stokastisk variabel X och på samma sätt kan punktskattningen ses som ett utfall av en stickprovsvariabel (där vi sätter in X istället för x i funktionen som definierar punktskattningen).Vi definierade begreppen väntevärdesriktighet, konsistens och effektivitet för punktskattningar och visade att stickprovsmedelvärdet och stickprovsvariansen kan användas som punktskattningar av väntevärdet och variansen. Vi avslutade med att diskutera maximum likelihood-metoden och minsta-kavdrat-metoden som är generella metoder för att härleda punktskattningar. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 8 (160421)Föreläsning 8 behandlade fyra diskreta fördelningarna, nämligen för-första-gången-fördelningen, binomialfördelningen, Poissonfördelningen och den hypergeometriska fördelningen.För för-första-gången-fördelningen beräknade vi väntevärdet och skrev ner variansen. För binomialfördelningen visade vi att Bin(n,p)-fördelade stokastiska variabler kan ses som en summa av n oberoende Be(p)-fördelade stokastiska variabler. Detta synsätt användes dels för att bestämma väntevärde och varians för binomialfördelade stokastiska variabler, dels för att kunna applicera centrala gränsvärdessatsen och visa att binomialfördelningen är asymptotiskt normalfördelad. Vi studerade därefter Poissonfördelningen som fås från binomialfördelningen om vi låter n gå mot oändligheten och p mot noll. Vi formularde en additionssats för Poissonfördelade stokastiska variabler och drog därefter slutsatsen att en normalapproximation är möjlig även för Poissonfördelade stokastiska variabler. Vi avslutade med att undersöka den hypergeometriska fördelningen och visade hur den uppkommer vid t ex kvalitetkontroll då man tar ett stickprov ur ett parti utan återläggning. Om partiet är mycket stort i förhållande till stickprovet blir den hypergeometriskt fördelade stokastiska variabeln approximativt binomialfördelad. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 7 (161116)Föreläsning 7 behandlade normalfördelningen. Vi noterade sedan att linjärkombinationer av oberoende normalfördelade stokastiska variabler är normalfördelade. Speciellt betyder det att det aritmetiska medelvärdet av oberoende normalfördelade stokastiska variabler är normalfördelat. Som varning för att det krävs någon form av oberoende för att summor av normalfördelade stokastiska variabler skall bli normalfördelade ges följande motexempel.Vi avslutade med att diskutera centrala gränsvärdessatsen, som säger att även aritmetiska medelvärden av n oberoende, likafördelade (men inte nödvändigtvis normalfördelade) stokastiska variabler är approximativt normalfördelade för stora värden på n. Figur 7 visar en jämförelse mellan sannolikhetsfunktionen för det aritmetiska medelvärdet av n oberoende Po(1)-fördelade stokastiska variabler och täthetsfunktionen för motsvarande normalfördelning. För den intresserade: Ett bevis av centrala gränsvärdessatsen med hjälp av Laplacetransform (momentgenererande funktion) samt ett bevis med hjälp av Fourier-transform (karakteristisk funktion). Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 6 (161114)Föreläsning 6 inleddes med att vi visade att väntevärdet är en linjär funktion, dvs att väntevärdet av en linjärkombination av stokastiska variabler är lika med en linjärkombination av väntevärdena av de stokastiska variablerna.Vi härledde formel för variansen av summan av två stokastiska variabler och definierade i samband med detta kovariansen och korrelationskoefficienten som mått på det linjära beroende mellan två stokastiska variabler. Vi visade att oberoende stokastiska variabler också är okorrelerade, dvs har kovarians noll. Vi gav reäkneregler för kovarianser. Avslutningsvis tittade vi på stora talens lag som säger att det aritmetiska medelvärdet av summor av oberoende, likafördelade stokastiska variabler konvergerar mot väntevärdet (jfr relativa frekvensers stabilitet). Figur 6 visar hur täthetsfunktionen för det aritmetiska medelvärdet av n oberoende N(1,1)-fördelade stokastiska variabler närmar sig väntevärdet 1 när n går mot oändligheten. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 5 (161109)Vi började med att definiera väntevärde, varians och standardavvikelse för diskreta och kontinuerliga stokastiska variabler.För funktioner av stokastiska variabler kan man befara att man först skulle behöva ta fram fördelningen för den nya stokastiska variabeln för att beräkna väntevärdet, men det slipper man enligt sats 5.1 i boken. Föreläsningen avslutades med att vi tittade på räkneregler för väntevärden och varianser. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 4 (160407)Föreläsningen inleddes med att definiera exponentialfördelningen och så räknades uppgift 3.22 a). Figur 3 visar några exempel på exponentialfördelningar med parametervärden 0.5, 1 respektive 1.5 ochDärefter infördes tvådimensionella stokastiska variabler och vi definierade simultana sannolikhets- och täthetsfunktionerna för diskreta respektive kontinuerliga tvådimensionella stokastiska variabler samt simultana fördelningsfunktionen. Vi definierade också de marginella sannolikhets- och täthetsfunktionerna. Vi definierade oberoende stokastiska variabler och såg hur oberoende kan avgöras från fördelnings-, sannolikhets- och täthetsfunktionerna. Vi undersökte sedan funktioner av stokastiska variabler. Speciellt undersökte vi fördelningen för maximum och minimum av ett antal likafördelade stokastiska variabler. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 3 (161104)På denna föreläsning infördes begreppet stokastisk variabel. Man skiljer på diskreta och kontinuerliga stokastiska variabler.Vi definierade först diskreta stokastiska variabler, vilka kan anta ett ändligt eller uppräkneligt oändligt antal olika värden. Vi definierade sannolikhetsfunktionen, undersökte dess egenskaper och bestämde sannolikhetsfunktionerna för binomialfördelningen och ffg-fördelningen. Figur 1 visar några exempel på binomialfördelningar med n = 20 och p = 0.1, p = 0.25, p = 0.5 respektive p = 0.75. Vi definierade även kontinuerliga stokastiska variabler, vilka kan anta alla värden i ett eller flera intervall på tallinjen. Vi kan tolka en kontinuerlig stokastisk variabel som att den totala sannolikhetsmassan är utspridd på tallinjen och fördelningen av sannolikhetsmassan bestäms av täthetsfunktionen. Sannolikheten att värdet på en kontinuerlig stokastisk variabel ligger i ett visst intervall fås genom att integrera täthetsfunktionen över intervallet i fråga. Oavsett om det är en diskret eller kontinuerlig stokastisk variabel definieras fördelningsfunktionen likadant. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 2 (161102)Föreläsning 2 inleddes med multiplikationsprincipen och kombinatorik. Vi gick igenom på hur många sätt som vi kan välja ut k element ur en mängd med n element om urvalet sker med respektive utan återläggning och med respektive utan ordning. OBS! fallet med återläggning och utan ordning är inte relevant för den här kursen.Sedan infördes betingade sannolikheter och vi visade satsen om total sannolikhet samt Bayes sats för att "vända på en betingning". Allra sist definierade vi oberoende händelser. Teorin för denna föreläsning finns i kapitel 2.5-2.8 Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar Föreläsning 1 (161031)Föreläsning 1 inleddes med en kort introduktion till ämnet matematisk statistik med ett exempel på en tillämpning av matematisk statistik. De begrepp som infördes finns i kapitel 10.1-10.3 beskrivande statistik.Sedan infördes de grundläggande sannolikhetsteoretiska begreppen slumpförsök, utfall, utfallsrum och händelse. Då händelser kan tolkas som mängder gick vi igenom mängdlärans operationer komplement, union och snitt. Vi gick igenom Kolmogorovs axiomsystem och några satser som följer ur detta samt diskuterade kopplingen mellan relativa frekvensen och sannolikheten för en händelse. Vi avslutade med den klassiska sannolikhetsdefinitionen som är användbar då utfallen kan anses vara lika sannolika. Teorin för detta finns i kapitel 2.1-2.4. Jimmy Olssons föreläsninganteckningar Thomas Önskogs föreläsninganteckningar Tatjana Pavlenkos föreläsningsanteckningar
|
 |
|
Sidansvarig: Tatjana Pavlenko Uppdaterad: 2013-07-27 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}