
|
Aktuell information för SF1906 och SF1831På denna sida presenteras aktuell information som vad som behandlats på föreläsningar samt schemaändringar.Tentamen 18/12-2009Tentan är rättad men i samband med inmatningen i betygssystemet LADOK blev det lite fel eftersom det bara rapporterades 6 poäng och inte 9 poäng, som det skulle ha varit. Detta kommer att korrigeras när helgerna är över. Här finns en rättningsnorm. Betygsgränserna var
Om ditt tentamensresultat inte finns via "Mina sidor" betyder det antagligen att du saknar kursregistrering och därmed inte kunnat läggas in i betygssystemet LADOK. Du måste kontakta studievägledningen för att ordna detta.
Anmälan till tentanAnmälan via "Mina sidor" kan göras 9/11-29/11. Observera att anmälan är obligatorisk och utan sådan är man ej garanterad plats på tentamen. Kolla gärna att du får upp kursen när du går in på "Mina sidor" för annars måste du kontakta studievägledare för att se vad som saknas vad gäller kursval etc.Anmälningstiden till tentan har gått ut och de som ej anmält sig får förlita sig på någon av reservplatserna. Kontrollskrivning nr 1Kontrollskrivning 1/10. Kontrollskrivningarna är rättade och har varit tillgängliga på en föreläsning och en övning. Överblivna finns nu på matteexpeditionen.Kontrollskrivning nr 2Kontrollskrivning nr 2 omfattade kapitel 7-13.Kontrollskrivningarna är rättade och har varit tillgängliga på en övning. Överblivna finns nu på matteexpeditionen. Föreläsningsinformation09-11-23 Sista föreläsningen! Köteori där speciellt M/M/1 och M/M/2 gicks igenom både via direkt kalkyl och via formelsamlingen. Littles formler "härleddes" och visade att dessa kan använda kunskap om (t ex) förväntad kölängd för att få förväntad kötid, förväntad tid i systemet samt förväntat antal i systemet.Pratade om Littles formler som ger möjlighet att av en av l, lq, w, wq beräkna de övriga. Gav ett intuitivt resonemang om hur dessa formler kan ses som tillämpning av principen "what goes in must come out", dvs att flöde in i systemet måste vara flöde ut ur systemet, t ex att (i asymptotiskt skede) λ=E(antal betjäningar)μ och att l=lq+E(antal betjäningar) samt att lq=λwq som kan tolkas som att när kunden kommer ser han lq kunder och ovanstående relation säger att att när han lämnar kön efter tiden wq har λwq kunder kommit och alltså står i kön. Pratade lite om M/M/c och dessutom om förlustsystem (t ex utan kö) där vissa kunder ej ansluter sig. Vidare lite om generalisering där anslutningssannolikheten varierar med antalet kunder i systemet och där betjäningsintensitetetn också varierar beroende på antalet (kassören/kassörskan "spruttar på" om många finns i systemet. Pratade om system med flera sorters kunder där man ej får födelse-dödsprocesser men som naturligtvis ändå kan analyseras. Spillde några ord om M/G/1-kön där man har allmän betjäningstidsfördelning. Gick igenom kopplade köer (Jackson-nätverk) med ett exempel om ett dator-system. 09-11-16 Införde Poissonprocessen som en matematisk modell för "händelser som inträffar fullständigt slumpmässigt i tiden" och framställde den på 3 olika sätt som kan visas vara ekvivalenta. Nämnde möjliga generaliseringar i form av 1) inhomogen Poissonprocess där sannolikheten per tidsenhet λ varierar med tiden 2) förnyelseprocess där tiderna mellan händelser är oberoende likafördelade men inte nödvändigtvis exponentialfördelade. Den i kursen aktuella generaliseringen är födelseprocesser som hoppar upp ett steg i taget och tiden mellan hopp nr k och nr k+1 är Exp(λk). Risken finns att en sådan process "exploderar", dvs hinner upp till oändligheten på ändlig tid - något som gör processen icke-reguljär. Födelse-döds-processer där övergångsintensitetsmatrisen Q har bandstruktur, dvs processen kan bara hoppa upp ("födelse") eller ner ("död") ett steg i taget. Som exempel gavs kösystemet M/M/1 där kunder anländer enligt en Poissonprocess, eventuellt köar och sen får betjäning som tar en exponentialfördelad tid. Villkor för att processen skall vara ergodisk, dvs att den har en unik gränsfördelning (asymptotisk fördelning) oavsett starttillstånd. Tog fram asymptotiska fördelningen för M/M/1-systemet direkt och gick igenom den allmänna algoritm som finns i formelsamlingen för att hitta den stationära fördelningen för födelse-dödsprocesser. Behandlade sedan M/M/2-systemet, dvs ett system där man har två parallella betjäningsstationer och en totalordnad kö samt har kundankomster enligt en Poissonprocess med intensitet λ. Visade hur Q-matrisen såg ut - återigen en födelse-dödsprocess och vi kunde få fram den stationära (asymptotiska) fördelningen med hjälp av algoritmen i formelsamlingen om λ<2μ som var krav för existens av stationärfördelning.
Ungefärligt innehåll. 09-11-08 Visade att Markovegenskapen (minneslösheten) medför att att uppehållstiden i ett tillstånd måste vara exponentialfördelad och härledde att denna måste ha intensitet qi=-qii. Det fantastiska är nu att det är lätt att få fram Q i en konkret situation samt elementen i Q är lätta att tolka. Gav ett exempel av tillförlighetskaraktär (Exempel 6.3 i kompendiet).
Beskrev hur man ur Q kan få fram P(t)-matrisen med hjälp av Kolmogorovs fram/bakåt-ekvationer samt hur man kan få ett system av kopplade differentialekvationer för de obetingade sannolikheterna dvs p'(t)=p(t)Q samt hur dessa ser ut i en kedja med Q enligt uppgift 34 i problemsamlingen. Beskrev även hur dynamiken ser ut i termer av Q-matrisen exemplifierad med problem 34.
Definierade ergodiska processer samt att en irreducibel kedja (eller mer allmänt att kedjan har bara en sluten irreducibel delklass) på ett ändligt E är ergodisk. För kedjor med oändligt E krävs också att det existerar en stationär fördelning. Notera att den inbäddade hoppkedjan mycket väl kan få vara periodisk. Definierade stationär fördelning och visade att den kan fås genom att lösa 0=πQ.Notera att man kan stryka godtycklig ekvation utom normeringsekvationen. Visade hur ekvationssystemet 0=πQ relaterade till ekvationssystemet π=πP(t) eftersom P(h)=I+hQ+o(h). Införde Poissonprocessen som en matematisk modell för "händelser som inträffar fullständigt slumpmässigt i tiden" och framställde den på 3 olika sätt som kan visas vara ekvivalenta. Nämnde möjliga generaliseringar i form av 1) inhomogen Poissonprocess där sannolikheten per tidsenhet λ varierar med tiden 2) förnyelseprocess där tiderna mellan händelser är oberoende likafördelade men inte nödvändigtvis exponentialfördelade.
Ungefärligt innehåll. 09-11-04 Beskrev lite översiktligt hur periodiska kedjor uppträden samt hur det allmänna uppträdandet av ändliga kedjor ser ut. Det finns ett antal slutna irreducibla delklasser samt (eventuellt) ett antal genomgångstillstånd. Med A-kedjemetodik kan man beräkna sannolikheten att absorberas i respektive sluten irreducibel delklass. Är dessa sen aperiodiska konvergerar fördelningen mot den stationära i respektive sluten irreducibel delklass. Pratade lite om uppträdandet av oändliga kedjor där en komplikation kan vara att kedjan glider ut mot oändligheten. Tillräckligt villkor för ergodicitet är att det existerar en stationär fördelning och att kedjan är irreducibel och aperiodisk. Inledning om kontinuerlig tid. Införde övergångssannolikheterna pij(t) som bildar matrisen P(t). Visade Chapman-Kolmogorovs ekvationer dvs P(s+t)=P(s)P(t) och konstaterade att detta innebär att det är svårt att ange P(t) direkt. Pratade lite om minneslöshet hos exponentialfördelningen. Införde felintensiteter och hur dessa kan tolkas, samt att exponentialfördelningen är den enda fördelningen med konstant felintensitet. Bevis för att minimum av exponentialfördelade är exponentialfördelad och att vilken som böir minst är oberoende av tiden till minimum. Visade att uppehållstiden i ett tillstånd för en Markovprocess måste vara exponentialfördelad eftersom detta är den enda minneslösa fördelningen. Ungefärligt innehåll. 09-11-02 Fortsättning om Markovkedjor i diskret tid.
Klassifikation av tillstånd för Markovkedjor, speciellt kommunicerande tillstånd (man kan gå fram och tillbaka mellan tillstånden) och irreducibla delklasser (alla tillstånd kommunicerar), slutna delklasser (inga pilar ut ur delklassen), Begreppet ergodisk kedja, dvs en där fördelning efter lång tid inte beror av startfördelningen. Visade att det alltid finns minst en sluten irreducibel delklass i en kedja med ändligt tillståndsrum E genom att utnyttja att tvåvägs-kommunikation är en ekvivalensrelation. För den intresserade finns här ett enkelt bevis för att en ändlig Markovkedja alltid har minst en stationär fördelning.
Satsen att en kedja med en enda sluten irreducibel delklass har en unik stationär fördelning. Begreppet period för ett tillstånd, dvs största gemensamma delare till de tänkbara utflyktlängderna från tillståndet. Om perioden är 1 kallas tillståndet aperiodiskt. Satsen att två tillstånd som kommunicerar har samma period. Huvudsatsen att en ändlig kedja är ergodisk om och endast om den bara har en enda sluten irreducibel delklass och denna är aperiodisk. Den asymptotiska fördelningen måste vara den stationära om kedjan är ergodisk, dvs kan fås genom att lösa (det överbestämda) ekvationssystemet π=πP samt normeringsekvationen. Nämnde att man kan stryka vilken ekvation som helst utom normeringsekvationen. Konvergensen mot den asymptotiska fördelningen går mycket snabbt. Ett enkelt kriterium för att kedjan skall vara ergodisk är att P har en fylld kolumn. Markovkedjor används för simulering inom Markov Chain Monte Carlo (MCMC) som är en mycket kraftfull och användbar teknik.
Visade att i fördelningen i en ergodisk kedja kan asymtotiska sannolikheterna πi fås som 1/E(Ti) där Ti är tiden mellan två besök i tillstånd i .
Nämnde att Googles sidsorteringsalgoritm Pagerank baseras på den stationära fördelningen i den Markovkedja som beskriver länkstrukturen på Internet. Denna erhålls dock inte genom att lösa ekvationssytemet utan i stället genom att stega sig fram genom upprepad multiplikation av övergångsmatrisen. Ungefärligt innehåll. 09-10-28 Introduktion till Markovteori. Allmänna stokastiska processer och markovegenskapen (minneslöshet). Markovprocesser med diskreta tillståndsrum (markovkedjor). Definierade viktiga begrepp, speciellt övergångsmatriser och obetingade sannolikheter och visade Chapman-Kolmogorovs ekvationer. Begreppet stationärfördelning, dvs en fördelning som uppfyller π=πP. Beskrev att huvudproblemet kommer att vara att uttala sig om Markovkedjans uppträdande efter lång tid. För den intresserade finns här ett enkelt bevis för att en ändlig Markovkedja alltid har minst en stationär fördelning. Inledning till absorption för vissa Markovkedjor och illustrerade med ett tärningsspel enligt uppgift 16 i kompendiet.
Ungefärligt innehåll. 09-10-26 Pratade om χ2-test. Illustrerades med exempel 13.18 sid 344 där man testade om data från en lustig och klassisk illustration om antalet ihjälsparkade kavallerister vid 14 tyska armékårer under en 20-årsperiod kom från en Poissonfördelning. Det sista med utgångspunkt från (den något förvirrade och okunniga) boken "The roots of coincidence" av Arthur Koestler. Förklaringen av att antalet kan antas vara Poissonfördelat är t ex att Bin(n,p) väl approximeras av Po(np). Man kan också göra en feluppskattning av denna typ av approximationer.
Behandlade vidare homogenitetstest (kontingenstabell) med ett exempel om analys av skillnaden mellan nyfödda pojkar och flickor vad gäller intresse för ansikten. Se tabell 1 i bifogade vetenskapliga artikel Sex differences in human neonatal social perception. där analysen sammanfattas som "χ2=8.3, df.=2, p=0.016", dvs värdet på teststorheten Q, antalet frihetsgradet (degrees of freedom) och p-värdet. p-värdet är sannolikheten att en χ2(2)-fördelad variabel är större än det observerade Q-värdet 8.3. Slutsatsen var alltså att nyfödda pojkar och flickor skiljde sig åt vad gäller intresset för ansikten om vi testar på en signifikansnivå (felrisk) över 0.016, t ex 5%. Lite om enkel linjär regression och visade hur formelsamlingen gav konfidensintervall för konstantterm (α), lutningskoefficient (β) samt en punkt på linjen. Nämnde lite om multipel regression (att anpassa ett plan till taltripplar) samt om att anpassa en andragradskurva till talpar. Nästa gång börjar vi med Markovprocesser (röda kompendiet). 09-10-14 Kapitel 13 om hypotesprövning, dvs statistisk bevisning. Grundbegreppen nollhypotes, alternativhyptotes, testvariabel, kritiskt område, fel av första slaget (α-felet), fel av andra slaget (β-felet), signifikansnivå (felrisk) illustrerades med två exempel: I samband med det första exemplet pekades på den i praktiska sammanhang ofta användbara "konfidensmetoden" att utföra hypotesprövning på nivån α genom att beräkna ett konfidensintervall med konfidensgrad (1-α). Inledning om χ2-test i form av test av fördelning som exemplifierades med ett test av en tärning i enlighet med exempel 13.17 i läroboken. Overheader från liknande kurs. 09-10-12 Konfidensintervall i situationen "ett normalfördelat stickprov med okänd spridning". Fick på köpet konfidensintervall för σ enligt FS 12.4 där χ2-fördelningen dök upp. Pratade lite om enkelsidiga intervall där man låter ena gränsen vara trivial och har α i stället för α/2 i percentilen. Tog sedan fram konfidensintervall för μ där Students t-fördelning dök upp. Två oberoende stickprov, dvs två dataserier som fick illustreras med fiktiva data på längder hos 100 svenska och 50 japanska män för att bedöma skillnaden i medellängd mellan svenska och japaner. Behandlade den väldigt allmänna modellen att vi hade två helt okända fördelningar där vi med hjälp av Centrala gränsvärdessatsen kunde få en skattning av skillnaden i medellängd som är approximativt normalfördelad och där vi fann en naturlig skattning för medelfelet och därefter kunde använda FS 12.3 (approximativa metoden) för att få ett konfidensintervall för skillnaden i medellängd. Slutligen den vanligaste (men kanske inte helt realistiska) modellen med normalfördelade observationer med okänd men lika spridning. Denna modell är ett specialfall av s k Variansanalys (Analysis of variance - ANOVA), där man sammanväger variansskattningarna. Avslutningsvis lite om "parvisa observationer" som på ett försåtligt sätt liknar "två oberoende stickprov". Utgör en vanlig källa till kraftiga avdrag på tentamina. Knepet är att bilda skillnaden inom par och därefter analysera dessa skillnader som ett stickprov. Overheader från liknande kurs. 09-10-05 Pratade lite om felfortplantning (Gauss-approximation) som i princip bygger på en linearisering. Kapitel 12 om konfidensintervall (intervallskattning) också kallade osäkerhetsintervall. Härledning av konfidensintervall då data är utfall av oberoende normalfördelade variabler N(μ,σ0) där spridningen σ0 är känd. Detta genomfördes som ett program i fem punkter. Resultatet framgår av formelsamlingens 12.1 λ-metoden. Approximativa konfidensintervall med exempel på opinionsundersökning. En mycket viktig situation som beskrivs av formelsamlingen i 12.3 Approximativa metoden där kontentan är att intervallet blir skattning ± 1.9600 medelfel om man vill göra ett approximativt 95%-igt konfidensintervall. Tillämpades på fallet med en opinionsundersökning. Tillämpades också som hastigst på jämförelse av två opinionsundersökningar. Hastig och hafsig introduktion av situationen då vi har normalfördelade data med okänd spridning som alltså måste skattas. I steg 3 av programmet för att ta fram konfidensintervall erhåller man (θ*-&theta)/(S/√n) som man med stor möda kan ta fram fördelningen för. Den kallas Students t-fördelning med n-1 frihetsgrader (som betecknas t(n-1)). Detta gjordes av Gosset som jobbade på Guinness bryggeri och som tvingades publicera resultatet under pseudonymen A.Student (en student). Utseendet framgår av följande bild av t(9)-fördelning som är tillämplig då vi har 10 mätdata. Percentiler finns i tabell 3 och man ser att om n=10 ersätts λ0.025≈1.9600 med t0.025(9)≈2.26. Mer om detta och andra situationer nästa gång.
Overheader från liknande kurs. 09-09-28 Kapitel 11 om punktskattningar. Opinionsundersökningsexemplet i enlighet med avsnitt 11.2 i läroboken. Begreppen väntevärdesriktigtighet samt medelfel och effektivitet. Visade att aritmetiskt medelvärde och stickprovsvarians var väntevärdesriktiga och konsistenta skattningar om data är oberoende likafördelade och man vill skatta μ=väntevärdet och σ2=variansen i den bakomliggande fördelningen. Det kan dock finnas effektivare skattningar och pekade på ett exempel. Maximumlikelihoodmetoden illustrerades med ett exempel med Poisson-fördelade mätdata. ML-metoden ger i princip de effektivaste skattningarna. För den intresserade ges här en (ganska svår) genomgång av teoretisk statistik. Minsta kvadratmetoden illustrerades som hastigast med exemplet enkel linjär regression
Overheader från liknande kurs. 09-09-21 Centrala gränsvärdessatsen illustrerad med poängsumma av många tärningskast. 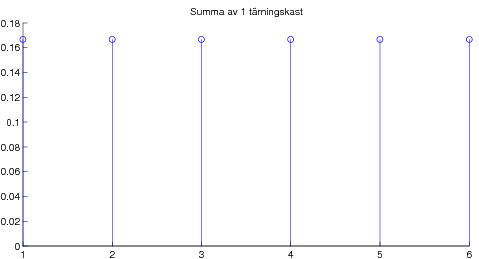 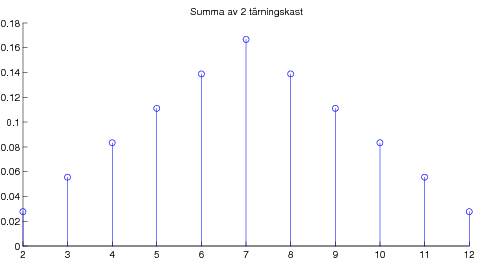 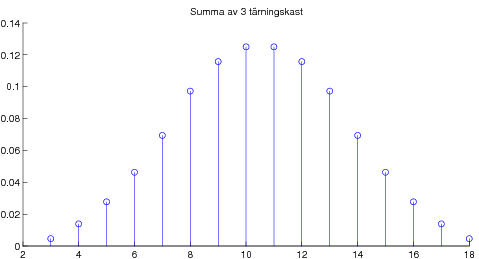 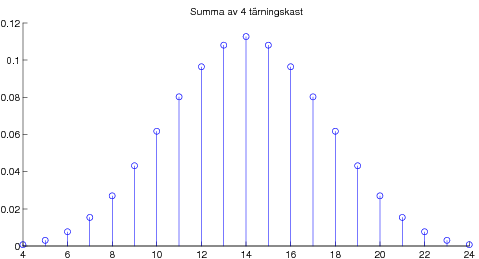 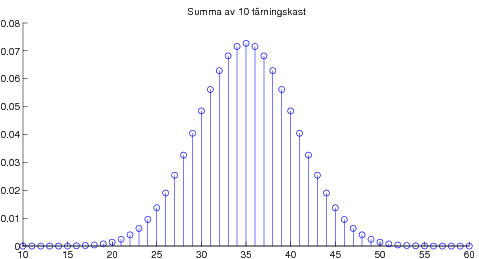 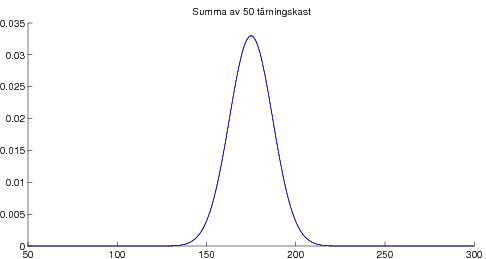
För den intresserade: Ett bevis av Centrala gränsvärdessatsen med hjälp av Laplacetransform (momentgenererande funktion) samt ett bevis med Fourier-transform (karaktäristisk funktion).
Kontrollskrivningen 1/10 omfattar just kapitel 1-6. Kapitel 7 om binomialfördelningen och dess släktingar. Binomialfördelning, Poissonfördelning och hypergeometrisk fördelning. Deras egenskaper och approximationer fördelningarna emellan samt normalapproximationer. Notera att vi kräver att ni lär er modellsituationerna för för binomial, ffg och hypergeometrisk fördelning. Ett bevis med användning av faltning för att summor av oberoende Poissonfördelade stokastiska variabler är Poissonfördelade skissades. Egentligen bör detta göras med "sannolikhetsgenererande funktioner" (z-transform). Feluppskattning för approximation av binomial- med Poisson-fördelning som motiverar varför Poisson-fördelning är så vanlig som modell för "sällsynta händelser". En lustig och klassisk illustration om antalet ihjälsparkade
kavallerister. Det sista med
utgångspunkt från (den något förvirrade och
okunniga) boken "The
roots of coincidence" av Arthur Koestler.
09-09-17 Införde C(X,Y)=kovariansen mellan X och Y som beroendemått där C(X,Y)=E((X-E(X))(Y-E(Y)))=E(XY)-E(X)E(Y) samt korrelationskoefficienten=C(X,Y)/(D(X)D(Y)) och varnade för okritisk användning av denna som mått på orsakssamband. Visade att oberoende variabler har kovarians=0, men gav ett exempel på att omvändningen inte gäller. Stora talens lag, dvs att aritmetiska medelvärdet av summor av oberoende likafördelade stokastiska variabler konvergerar mot väntevärdet, vilket är en viktig tolkning av väntevärdet. Som specialfall kan man ta "relativa frekvensers stabilitet" som vi talade om i kapitel 2.
Kapitel 6 om normalfördelningen. Definition och egenskaper, speciellt egenskapen att alla linjärkombinationer av oberoende normalfördelade stokastiska variabler är normalfördelade. Lite om användningen av Φ-tabell dvs tabell över fördelningsfunktionen för den standardiserade normalfördelningen N(0,1). Som varning att det krävs någon form av oberoende för att summor av normalfördelade skall bli normalfördelad ges följande motexempel. Som extra bonus införde jag den s k sannolikhetsgenererande funktionen och visade hur den kan användas för att beräkna fördelningen för summan av oberoende stokastiska variabler. Material från en liknande kurs. 09-09-14 Kapitel 5 om väntevärden. Beräknade väntevärdet i Po(μ)-fördelningen. Gick igenom S:t Petersburgsparadoxen i enlighet med Exempel 5.8 i läroboken. Införde variansen och standardavvikelsen som spridningsmått. Räkneregler för väntevärde och varians varvid begreppet kovarians dök upp som mått på beroende.
Visade räknelagar för väntevärden och varianser:
Observera att V(X - Y) = V(X) + V(Y) om X och Y är oberoende. Varians är alltså inte en linjär operation!!! Material från en liknande kurs. 09-09-11 Repeterade från kapitel 3 begreppen sannolikhetsfunktion, täthetsfunktion och fördelningsfunktion. Tog fram fördelningsfunktion för Exp(λ)-fördelningen. Behandlade funktioner av stokastiska variabler med exemplen Y="X tecken" (exempel 3.17 i boken), samt Y=X2 enligt exempel 3.21. Kapitel 4 om flerdimensionella stokastiska variabler. Begreppen simultan sannolikhetsfunktion och simultan täthetsfunktion samt hur de vanliga (marginella) sannolikhetsfunktionerna respektive täthetsfunktionerna kan får ur dess. Begreppet oberoende stokastiska variabler med exemplet "två tärningskast". Funktioner av flera oberoende stokastiska variabler med exemplen max(X,Y) samt min(X,Y) samt (lite slarvigt) X+Y. Borde ha hunnit börja på kapitel 5 men det får bli på måndag. Material från en liknande kurs. 09-09-07 Kapitel 3 om stokastiska variabler. För diskreta stokastiska variabler behandlades och exemplifierades med
Begreppet fördelningsfunktion dvs FX(x)=P(X≤x) som kan användas för att beräkna
Lite om uppräknelighet.
Material från en liknande kurs.
09-09-04 Repeterade klassiska sannolikhetsdefinitionen. Lite om kombinatorik. Gick igenom 3 av de 4 kombinationerna av med/utan hänsyn till ordning och med/utan återläggning. Här är den sista kombinationen dvs med återläggning och utan hänsyn till ordning - som saknar intresse i kursen. De olika möjligheterna i detta 4:e fall är dessutom inte lika sannolika i urnmodeller vilket innebär att den saknar intresse för klassiska sannolikhetsdefinitionen. Betingad sannolikhet, lagen om total sannolikhet samt Bayes sats, där betingade sannolikheter illustrerades med hjälp av data om mail (spam eller icke-spam) som innehöll texten "Free" respektive inte innehöll texten "Free". Bayes sats illustrerades med hjälp av data om diagnostiskt test. Läs gärna godiset om bilen och getterna som är en illustration av betingad sannolikhet. Begreppet oberoende händelser, dvs sådana som inte ger information om varandra (påverkar inte sannolikheterna). Visade att komplementen till oberoende händelser också är oberoende. På övningarna har ni ju räknat det klassiska "födelsedagsproblemet" och ett föredrag i den andan är Persi Diaconis föredrag On coincidences från Princeton. Här är en DN-artikel om när Persi Diaconis var i Sverige och föreläste om och trollade med slantsingling. Material från en liknande kurs. 09-09-02 Grundläggande terminologi. Slumpförsök, utfall, utfallsrum och händelse med exempel på diskreta utfallsrum (ändliga eller uppräkneligt oändliga). Tolkning av mängder som händelser och mängdlärans operationer: komplement, union och snitt. De Morgans lagar. Omöjliga och oförenliga (disjunkta) händelser. Relativa frekvensers stabilitet. Tolkning av sannolikhetsbegreppet. Kolmogorovs axiomsystem och några satser som följer ur detta. Klassisk sannolikhetsdefinition som är tillämplig då elementarutfallen kan antas vara lika sannolika. Lite om kombinatorik. Overheader från liknande kurs. Material från en liknande kurs.
|
 |
|
Sidansvarig: Gunnar Englund Uppdaterad: 2008-08-18 |