
|
|
Aktuell information för SF1906 och SF1831
Kontrollskrivning nr 1Kontrollskrivning 1 ges 2/10 kl 15-17 i ordinarie övningssalar samt V21 och V23.Skrivningen omfattar kapitel 1-6. Tillåtet och rekommenderat hjälpmedel är räknare. Observera att formelsamlingen inte är tillåtet hjälpmedel. Tabellerna 1 och 2 om normalfördelningen kommer att finnas på baksidan av textlappen.Som träning ges här några exempel på kontrollskrivningar: Man kan också som träning lösa gamla tentatal som behandlar kapitel 1-6.Föreläsningsinformation08-10-16 Avslutade kapitel 12 med en fyllig genomgång av "parvisa observationer" och påpekade vikten av att kunna skilja detta fall från "två oberoende stickprov". Kapitel 13 om hypotesprövning, dvs statistisk bevisning. Grundbegreppen nollhypotes, alternativhyptotes, testvariabel, kritiskt område, fel av första slaget (α-felet), fel av andra slaget (β-felet), signifikansnivå (felrisk) illustrerades med två exempel: I samband med det andra exemplet pekades på den i praktiska sammanhang ofta användbara "konfidensmetoden" att utföra hypotesprövning på nivån α genom att beräkna ett konfidensintervall med konfidensgrad (1-α). Overheader från liknande kurs. 08-10-15 Konfidensintervall i situationen "ett normalfördelat stickprov med okänd spridning". Fick på köpet konfidensintervall för σ enligt FS 12.4 där χ2-fördelningen dök upp. Pratade lite om enkelsidiga intervall där man låter ena gränsen vara trivial och har α i stället för α/2 i percentilen. Tog sedan fram konfidensintervall för μ där Students t-fördelning dök upp. Två oberoende stickprov, dvs två dataserier som fick illustreras med fiktiva data på längder hos 100 svenska och 50 japanska män för att bedöma skillnaden i medellängd mellan svenska och japaner. Behandlade först den (helt orealistiska) modellen att observationerna kom från två normalfördelningar med kända spridningar och använde så FS 12.1 λ-metoden. Behandlade sen den väldigt allmänna modellen att vi hade två helt okända fördelningar där vi med hjälp av Centrala gränsvärdessatsen kunde få en skattning av skillnaden i medellängd som är approximativt normalfördelad och där vi fann en naturlig skattning för medelfelet och därefter kunde använda FS 12.3 (approximativa metoden) för att få ett konfidensintervall för skillnaden i medellängd. Slutligen den vanligaste (men kanske inte helt realistiska) modellen med normalfördelade observationer med okänd men lika spridning. Denna modell är ett specialfall av s k Variansanalys (Analysis of variance - ANOVA), där man sammanväger variansskattningarna. Avslutningsvis lite om "parvisa observationer" som på ett försåtligt sätt liknar "två oberoende stickprov". Utgör en vanlig källa till kraftiga avdrag på tentamina. Knepet är att bilda skillnaden inom par och därefter analysera dessa skillnader som ett stickprov. Overheader från liknande kurs. 08-10-08 Kapitel 12 om konfidensintervall (intervallskattning) också kallade osäkerhetsintervall. Härledning av konfidensintervall då data är utfall av oberoende normalfördelade variabler N(μ,σ0) där spridningen σ0 är känd. Detta genomfördes som ett program i fem punkter. Resultatet framgår av formelsamlingens 12.1 λ-metoden. Approximativa konfidensintervall med exempel på opinionsundersökning. En mycket viktig situation som beskrivs av formelsamlingen i 12.3 Approximativa metoden där kontentan är att intervallet blir skattning ± 1.9600 medelfel om man vill göra ett approximativt 95%-igt konfidensintervall. Tillämpades också på jämförelse av två opinionsundersökningar. Hastig och hafsig introduktion av situationen då vi har normalfördelade data med okänd spridning som alltså måste skattas. I steg 3 av programmet för att ta fram konfidensintervall erhåller man (θ*-&theta)/(S/√n) som man med stor möda kan ta fram fördelningen för. Den kallas Students t-fördelning med n-1 frihetsgrader (som betecknas t(n-1)). Detta gjordes av Gosset som jobbade på Guinness bryggeri och som tvingades publicera resultatet under pseudonymen A.Student (en student). Utseendet framgår av följande bild av t(9)-fördelning som är tillämplig då vi har 10 mätdata. Percentiler finns i tabell 3 och man ser att om n=10 ersätts λ0.025≈1.9600 med t0.025(9)≈2.26. Mer om detta och andra situationer nästa gång.
Overheader från liknande kurs. 08-09-29 Kapitel 11 om punktskattningar. Opinionsundersökningsexemplet i enlighet med avsnitt 11.2 i läroboken. Begreppen väntevärdesriktigtighet samt medelfel och effektivitet. Visade att aritmetiskt medelvärde och stickprovsvarians var väntevärdesriktiga och konsistenta skattningar om data är oberoende likafördelade och man vill skatta μ=väntevärdet och σ2=variansen i den bakomliggande fördelningen. Det kan dock finnas effektivare skattningar och pekade på ett exempel. Maximumlikelihoodmetoden illustrerades med ett exempel med Poisson-fördelade mätdata. ML-metoden ger i princip de effektivaste skattningarna. För den intresserade ges här en (ganska svår) genomgång av teoretisk statistik. Minsta kvadratmetoden illustrerades dels med exemplet enkel linjär regression
Overheader från liknande kurs. 08-09-22 Kapitel 7 om binomialfördelningen och dess släktingar. Binomialfördelning, Poissonfördelning och hypergeometrisk fördelning. Deras egenskaper och approximationer fördelningarna emellan samt normalapproximationer. Notera att vi kräver att ni lär er modellsituationerna för för binomial, ffg och hypergeometrisk fördelning. Ett bevis med användning av faltning för att summor av oberoende Poissonfördelade stokastiska variabler är Poissonfördelade skissades. Egentligen bör detta göras med "sannolikhetsgenererande funktioner" (z-transform). Feluppskattning för approximation av binomial- med Poisson-fördelning som motiverar varför Poisson-fördelning är så vanlig som modell för "sällsynta händelser". En lustig och klassisk illustration om antalet ihjälsparkade
kavallerister. Det sista med
utgångspunkt från (den något förvirrade och
okunniga) boken "The
roots of coincidence" av Arthur Koestler.
Kapitel 8 ingår ej (men är skojigt och användbart i praktiska livet). Kapitel 9 och 10 läses kursivt. Inledning om kapitel 11 Punktskattningar med begreppen parameter, statistisk modell, punktskattning och stickprovsvariabel. Gav exemplet med observationer av antalet telefonanrop till en telefonsstation under 10 likartade enminutersperioder där vi ansatte modellen att antalet anrop under en enminutsperiod är Poissonfördelat Po(θ) och att det är oberoende mellan olika enminutersperioder. Vi skattade θ med punktskattningen θ*obs=aritmetiska medelvärdet
08-09-17 Avslutade kapitel 5 om väntevärden. Stora talens lag, dvs att aritmetiska medelvärdet av summor av oberoende likafördelade stokastiska variabler konvergerar mot väntevärdet, vilket är en viktig tolkning av väntevärdet. Som specialfall studerade vi begreppet "relativa frekvensers statibilitet" från kapitel 2. Bevisade också Tjebyshovs olikhet som är användbar i beviset av Stora Talens Lag (i svag form). För den intresserade: Ett ganska avancerat godis om bl a bevis av Stora Talens lag i stark form. Kapitel 6 om normalfördelningen. Definition och egenskaper, speciellt egenskapen att alla linjärkombinationer av oberoende normalfördelade stokastiska variabler är normalfördelade. Lite om användningen av Φ-tabell dvs tabell över fördelningsfunktionen för den standardiserade normalfördelningen N(0,1). Som varning att det krävs någon form av oberoende för att summor av normalfördelade skall bli normalfördelad ges följande motexempel. Centrala gränsvärdessatsen illustrerad med poängsumma av många tärningskast. 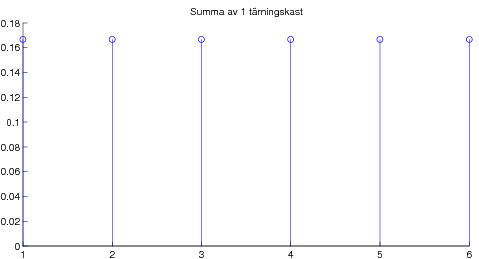 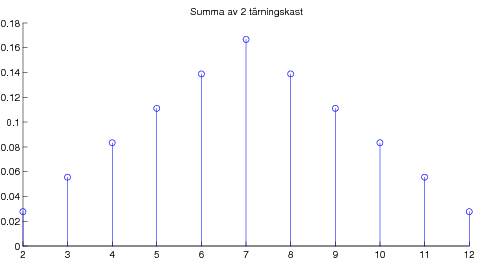 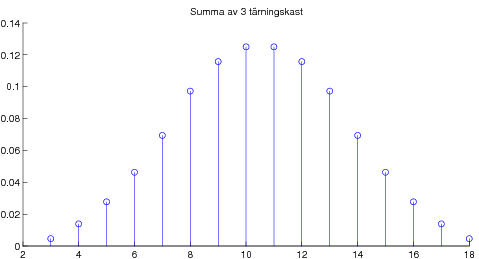 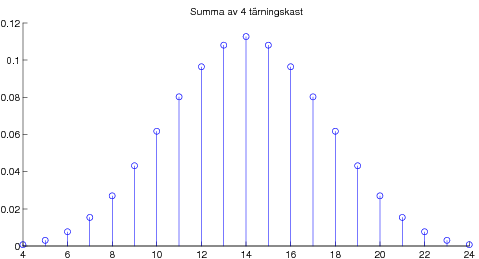 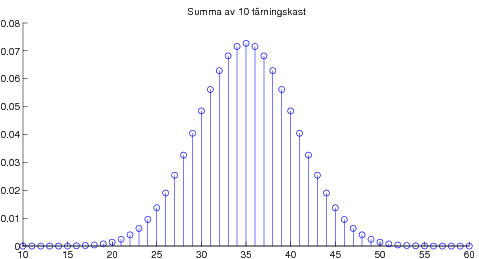 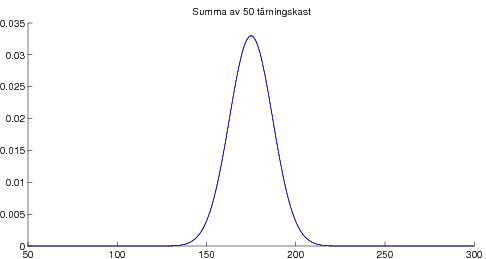
Kontrollskrivningen 2/10 omfattar just kapitel 1-6. För den intresserade: Ett bevis av Centrala gränsvärdessatsen med hjälp av Laplacetransform (momentgenererande funktion) samt ett bevis med Fourier-transform (karaktäristisk funktion). 08-09-15 Kapitel 5 om väntevärden. Beräknade väntevärdet i Po(μ)-fördelningen. Gick igenom S:t Petersburgsparadoxen i enlighet med Exempel 5.8 i läroboken. Införde variansen och standardavvikelsen som spridningsmått. Räkneregler för väntevärde och varians varvid begreppet kovarians dök upp som mått på beroende.
Visade räknelagar för väntevärden och varianser:
Införde också korrelationskoefficient och varnade för okritisk användning av denna som mått på orsakssamband. Overheader från liknande kurs. 08-09-11 Repeterade från kapitel 3 begreppen sannolikhetsfunktion, täthetsfunktion och fördelningsfunktion. Tog fram fördelningsfunktion för Exp(λ)-fördelningen. Behandlade funktioner av stokastiska variabler med exemplen Y="X tecken" (exempel 3.17 i boken), samt Y=X2 enligt exempel 3.21. Kapitel 4 om flerdimensionella stokastiska variabler. Begreppen simultan sannolikhetsfunktion och simultan täthetsfunktion samt hur de vanliga (marginella) sannolikhetsfunktionerna respektive täthetsfunktionerna kan får ur dess. Begreppet oberoende stokastiska variabler med exemplet "två tärningskast". Funktioner av flera oberoende stokastiska variabler med exemplen max(X,Y) samt min(X,Y) samt X+Y. Inledning om kapitel 5 (Väntevärden) med definition och tolkningar av väntevärde. Beräknade väntevärdet för summan av två tärningskast. Satsen om hur man beräknar E(g(X)). Overheader från liknande kurs. 08-09-08 Kapitel 3 om stokastiska variabler. För diskreta stokastiska variabler behandlades och exemplifierades med
Begreppet fördelningsfunktion dvs FX(x)=P(X≤x) som kan användas för att beräkna
Lite om uppräknelighet. Overheader från liknande kurs. 08-09-03 Betingad sannolikhet, lagen om total sannolikhet samt Bayes sats, där betingade sannolikheter illustrerades med hjälp av data om mail (spam eller icke-spam) som innehöll texten "Free" respektive inte innehöll texten "Free". Bayes sats illustrerades med hjälp av data om diagnostiskt test. Läs gärna godiset om bilen och getterna som är en illustration av betingad sannolikhet. Begreppet oberoende händelser, dvs sådana som inte ger information om varandra (påverkar inte sannolikheterna). Visade att komplementen till oberoende händelser också är oberoende. Inledning om kapitel 3 om det viktiga begreppet stokastisk variabel (typiskt betecknad X) som illustrerades med X="summan av två tärningskast" som är ett exempel på diskret fördelning där antalet tänkbara värden är ändligt (eller uppräkneligt oändligt) och det naturliga sättet att beskriva sannolikhetsfördelningen är att ange vilka värden som är möjliga samt hur sannolika de är, dvs med den s k sannolikhetsfunktion pX(k)=P(X=k) för alla tänkbara k. För exemplet om summan av två tärningskast blir sannolikhetsfunktionen så här. På övningarna har ni ju räknads det klassiska "födelsedagsproblemet" och ett föredrag i den andan är Persi Diaconis föredrag On coincidences från Princeton. Här är en DN-artikel om när Persi Diaconis var i Sverige och föreläste om och trollade med slantsingling. Overheader från liknande kurs. 08-09-01 Grundläggande terminologi. Slumpförsök, utfall, utfallsrum och händelse med exempel på diskreta utfallsrum (ändliga eller uppräkneligt oändliga). Tolkning av mängder som händelser och mängdlärans operationer: komplement, union och snitt. De Morgans lagar. Omöjliga och oförenliga (disjunkta) händelser. Relativa frekvensers stabilitet. Tolkning av sannolikhetsbegreppet. Kolmogorovs axiomsystem och några satser som följer ur detta. Klassisk sannolikhetsdefinition som är tillämplig då elementarutfallen kan antas vara lika sannolika. Lite om kombinatorik. Gick igenom 3 av de 4 kombinationerna av med/utan hänsyn till ordning och med/utan återläggning. Här är den sista kombinationen dvs med återläggning och utan hänsyn till ordning - som saknar intresse i kursen. Overheader från liknande kurs. |
 |
|
Sidansvarig: Gunnar Englund Uppdaterad: 2008-08-18 |
